Thought, Action, Observation: The Loop Behind Every Useful AI Agent
An AI that only reasons hallucinates; one that only acts is aimless. The ReAct loop — Thought → Action → Observation — braids them together, grounding every step in what actually happened.
 Adepeju Peace Orefejo
Adepeju Peace Orefejo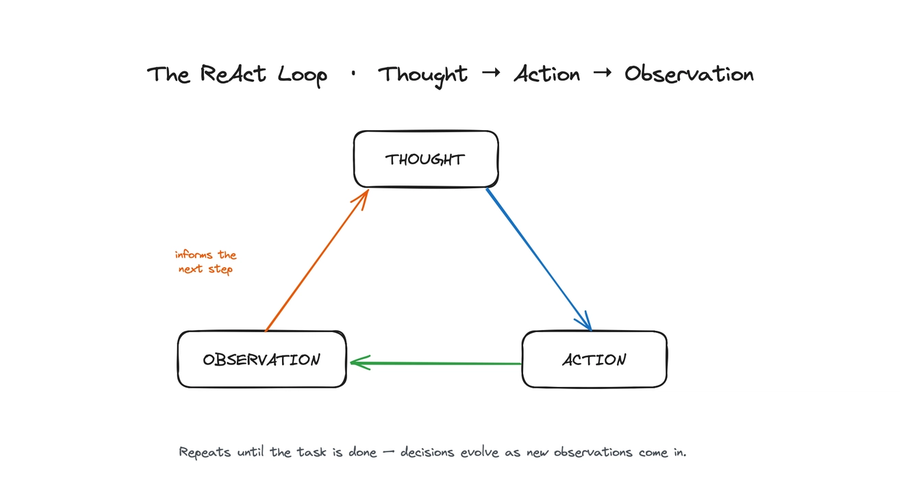
Thought, Action, Observation: The Loop Behind Every Useful AI Agent
"AI agents" sound complicated, and most of the flashy demos look like magic — for about thirty seconds. Then the agent confidently does something dumb. And honestly? It almost always fails for one of two reasons: it reasons without ever checking reality, or it acts without reasoning about what it's doing.
The fix for both is one small loop. It's easy to overlook, but once you see it, you'll spot it everywhere. It's called ReAct, and I want to walk you through it the way it finally made sense to me.
Two ways an agent goes wrong
Picture an agent that can only reason. You ask, "what's the train delay on my line right now?" and it hands you a fluent, specific, completely made-up answer — because pure chain-of-thought has no line to the outside world. The logic is airtight; the facts are fiction.
Now flip it. An agent that can only act fires off tools and API calls all day, but never stops to ask which one, why, or whether it's actually done. It's all motion and no judgment — like mashing buttons without reading the screen.
Real work needs both: the judgment to pick a move, and the reach to check it. That's exactly what ReAct — Reasoning + Acting, from Yao et al. (2022) — braids into a single loop.
The loop: Thought → Action → Observation
Here's the whole thing. ReAct runs an agent as a repeating three-beat cycle, and each beat has one job:
- Thought — the model reasons about its next move (not the final answer). What to do, and why.
- Action — it actually does that thing: runs a search, calls an API, queries a database, makes a calculation.
- Observation — it reads back what came back (a snippet, some JSON, an error) and treats it as fresh evidence.
The magic — if you can call a loop magic — is that each observation flows straight into the next Thought. The agent reasons again, now standing on something it genuinely saw, and keeps going until it's done. It never locks in a full plan up front. It takes one informed step, looks at what really happened, and decides the next one from there.
Watch it work
Say you ask: "Which of the two most populous countries has more people, and by how much?" Here's the agent thinking out loud:
Thought: I need the two most populous countries first.
Action: search("most populous countries 2026")
Observation: "1. India 2. China ..."
Thought: Now I need each country's population.
Action: lookup("population of India"), lookup("population of China")
Observation: India ≈ 1.46B ; China ≈ 1.41B
Thought: India is larger. Compute the gap.
Action: calculate(1.46B - 1.41B)
Observation: ≈ 50,000,000
Thought: I can answer now.
Answer: India has ~50 million more people than China.Notice that every number in the final answer traces back to something an action actually returned. The agent didn't guess the populations — it went and got them. That's the line between an answer you can ship and one that just sounds right.
What happens when it goes wrong
Here's where the loop really earns its keep — when a tool hands back the unexpected:
Thought: I'll find the launch date of the Vega-3 satellite.
Action: search("Vega-3 satellite launch date")
Observation: No exact match. Closest: "Vega C rocket, maiden flight 2022."
Thought: That's a different vehicle — my query was off. Narrow it.
Action: search("Vega-3 smallsat mission launch")
Observation: "Vega-3 deployed on the Vega C flight, July 2022."
Thought: Now I have a grounded answer.
Answer: Vega-3 launched in July 2022, aboard a Vega C rocket.A reason-only model would have blurted out a confident date and moved on. The ReAct agent caught the mismatch in the observation and corrected itself before answering. That's the real payoff: the agent is allowed to be wrong on step one and still right by the end.
You've probably already built one
Here's the part that made it click for me: this isn't some exotic framework you have to install. It's the shape almost every tool-using agent already takes. The tool-calling loop in a chatbot I built runs this exact cycle — the model decides to call a function (Thought), my code runs it (Action), the result goes back into the conversation (Observation), and the model carries on. Once you recognize ReAct as the thing underneath, agents stop being black boxes you poke at and start being systems you can actually reason about, debug, and extend.
Stripped to its skeleton, the whole pattern is about ten lines:
context = [user_question]
while True:
thought = model.respond(context) # Thought: reason, maybe pick a tool
if thought.is_final:
break # done — return the answer
result = run_tool(thought.tool_call) # Action: execute in the real world
context.append(result) # Observation: feed it back inNo framework, no magic — just a loop that keeps handing the model what actually happened until it has enough to answer. Everything else (LangChain, LangGraph, the Agent SDKs) is ergonomics on top of this.
Why braiding them together wins
Putting reasoning and acting in one cycle buys you three things:
- The two halves sharpen each other. Good reasoning picks the right action; the result of that action makes the next round of reasoning smarter. Neither side is flying blind.
- It adapts on the fly. Every step gets chosen after the last observation, so the agent can change its mind when reality disagrees with it — instead of marching down a plan it committed to before it knew anything.
- It hallucinates less. When the next step has to be grounded in what a tool genuinely returned, there's far less room to invent. The observations act like guardrails.
That third one is what separates a cute demo from something you'd actually put in front of a user: reliable agents stay tied to what happened, not to what the model assumes is true.
Where ReAct costs you
ReAct isn't free, and honestly, knowing when not to reach for it matters just as much as knowing how it works:
- It's slower and pricier. Every turn of the loop is another model call. For a question the model can answer in one shot, wrapping it in a Thought→Action→Observation cycle is pure overhead.
- It can run away. Nothing inherently stops the loop — a confused agent will happily spin forever. In practice you cap it with a max number of steps and a clear stopping condition.
- It's only as good as its tools. Vague tool descriptions, noisy outputs, or a tool that returns something misleading will quietly derail the whole chain — the agent reasons faithfully over bad evidence.
- The reasoning is chatty. All those Thoughts cost tokens, and they're not always something you want a user to see.
None of this is a reason to avoid ReAct. It's a reason to use it on purpose — for genuinely multi-step, open-ended tasks where the agent needs to look before it leaps, not for one-shot answers it already knows.
Reason-only vs. Act-only vs. ReAct
If it helps to hold three agents side by side:
- Reason-only — thinks step by step, never acts. Failure: confident hallucination.
- Act-only — calls tools, never reasons. Failure: busy but aimless.
- ReAct — reasons, acts, observes, repeats. Failure: honestly, not many — it course-corrects as evidence comes in.
ReAct doesn't win by being fancier. It wins because its decisions evolve as evidence shows up — which is exactly why it shines on open-ended work like research and multi-step search, where you can't know the full plan before you start.
The engine vs. the car
The loop is the engine. A production agent wraps a whole chassis around it: deciding which tool to call (routing), recovering when one fails (fallbacks), and logging, retrying, and guarding each step (middleware). That orchestration layer is a whole post of its own — Part 2.
But the engine comes first, and it's almost embarrassingly simple. Strip the jargon and a capable agent is doing something disciplined and very human: it thinks, acts, looks at what happened, and goes again — getting a little less wrong every time around.
References & further reading
Cited in this post
- Yao, S. et al. (2022). ReAct: Synergizing Reasoning and Acting in Language Models. arXiv:2210.03629 — arxiv.org/abs/2210.03629
Go deeper
- Wei, J. et al. (2022). Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. arXiv:2201.11903 — the "reason-only" mode, formalized. link
- Schick, T. et al. (2023). Toolformer: Language Models Can Teach Themselves to Use Tools. arXiv:2302.04761 — how a model learns the "act" half. link
- Shinn, N. et al. (2023). Reflexion: Language Agents with Verbal Reinforcement Learning. arXiv:2303.11366 — extends the loop: agents that reflect on observations to improve next time. link
- Anthropic (2024). Building Effective Agents — practical, framework-agnostic patterns for the orchestration layer (Part 2 territory). anthropic.com/engineering/building-effective-agents